Gradient-based Analysis of NLP Models is Manipulable
Many modern interpretation techniques rely on gradients as they are often seen as faithful representations of a model: they depend on all of the model parameters, are completely faithful when the model is linear, and closely approximate the model nearby an input. We show that even these “faithful” interpretations can be manipulated to be completely unreliable indicators of a model’s actual reasoning. We apply our technique to text classification, NLI, and Question Answering.
Our Method
Given an off-the-shelf language model (e.g., BERT), we merge this model with a model we call “Facade”.
The
gradients
of the Facade are trained to be adversarial (e.g., focus on only the first token in the sentence), while
its
outputs
are kept uniform. This way, the resulting merged model (original + Facade) has the same behavior as the
original
model, but its gradients will be dominated by the Facade! The figure below summarizes our attack.
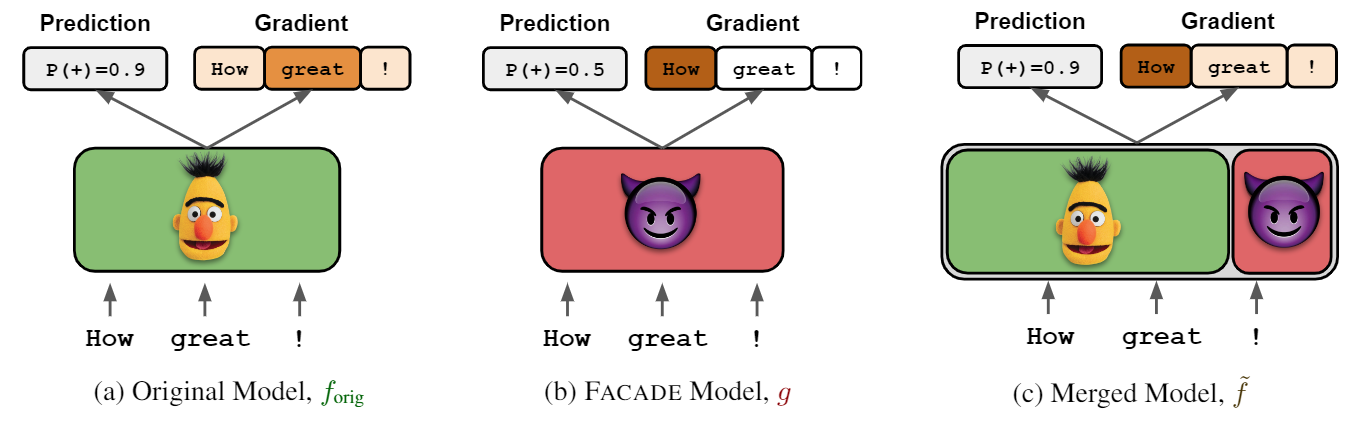
To guarantee that the behavior of the model stays the same after merging, we carefully intertwine the weights of the original model and the Facade, and only sum at the output layer (see paper for details).
Qualitative Results
Our technique fools many popular gradient-based interpretation techniques such as Gradient, SmoothGrad, and Integrated Gradient, though the last one is less affected. Our method also causes input reduction to reduce to unimportant tokens, and hotflip to require more perturbations to change the model prediction.

For the example above, we take a BERT-based sentiment classifier and merge its weights with a Facade. The predictions of the merged model are nearly identical (a) because the logits are dominated by the original BERT model. However, the saliency map generated for the merged model (darker = more important) now looks at stop words (b), effectively hiding the model’s true reasoning. Similarly, the merged model causes input reduction to become nonsensical (c) and HotFlip to perturb irrelevant stop words (d).
Paper Authors




