UCI
NLP
Publications
Videos
Awards
Members
Join Us
Talks & Demos
Interactive demos, tutorials, and recorded talks from the group.
Demos
Tutorials
Long Talks
Paper Talks
Demos
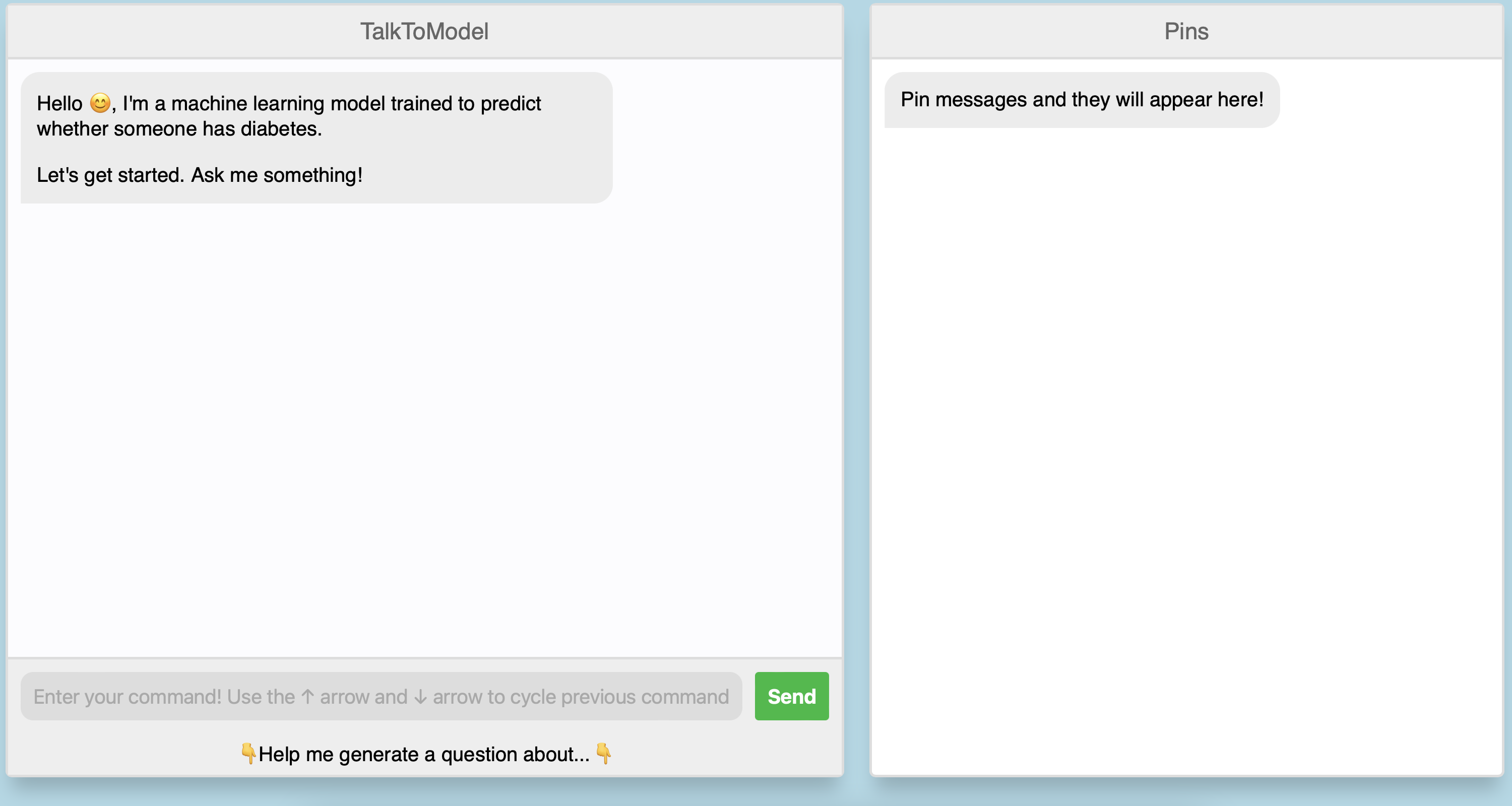
TalkToModel
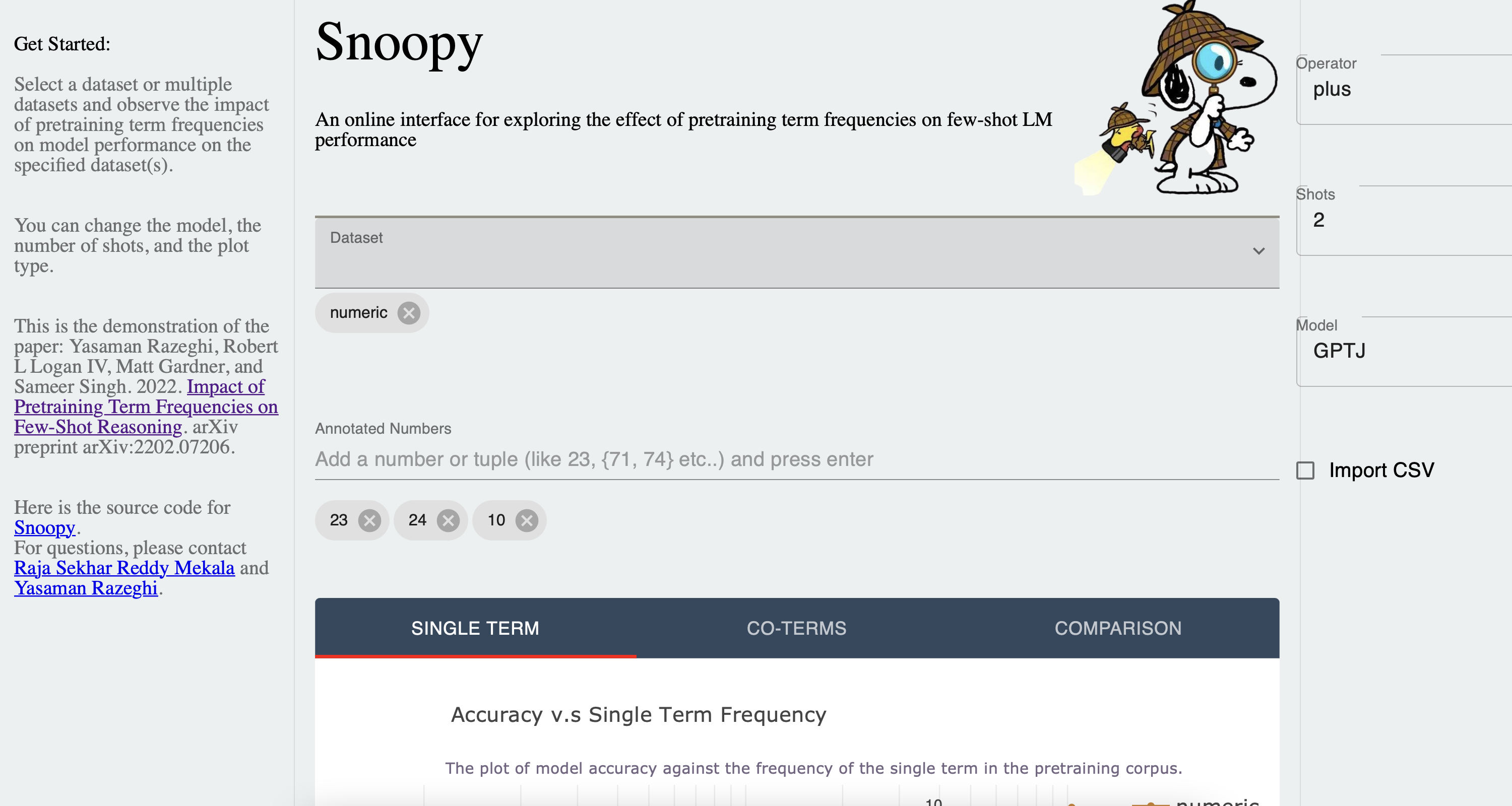
Snoopy
Tutorials
EMNLP 2020 Tutorial on Interpreting Predictions of NLP Models
by Eric Wallace, Matt Gardner, Sameer Singh
(EMNLP 2020)
AAAI 2021 Tutorial on Explaining Machine Learning Predictions
by Himabindu Lakkaraju, Julius Adebayo, Sameer Singh
(AAAI 2021)
NeurIPS 2020 Tutorial on Explaining ML Predictions: State-of-the-art, Challenges, and Opportunities
by Himabindu Lakkaraju, Julius Adebayo, Sameer Singh
(NeurIPS 2020)
Long Talks
Explaining in the Dark: Perils of Interpretability Without Training Data
by Sameer Singh
(EnCORE Workshop on Interpretability in Modern AI 2026)
How large language models work (and why that's why they don't)
by Sameer Singh
(IEEE Orange County Computer Society, SIGAI OC and the Los Angeles Chapter of the ACM)
Exposing Shortcomings and Improving Reliability of ML Explanations
by Dylan Slack
(Stanford MedAI)
Fooling LIME and SHAP Adversarial Attacks on Post hoc Explanation Methods
by Dylan Slack
(Aggregate Intellect)
Evaluating and Testing Natural Language Processing Models
by Sameer Singh
(IndoML 2021)
Yasaman Razeghi and Sameer Singh - NLP benchmarks
by Yasaman Razeghi, Sameer Singh
(Machine Learning Street Talk)
How to Win LMs and Influence Predictions
by Sameer Singh
(Repl4NLP 2021 Invited Talk)
Paper Talks
Nudging: Inference-time Alignment of LLMs via Guided Decoding
by Yu Fei
(ACL 2025)
Are Models Biased on Text without Gender-related Language?
by Catarina Belem
(ICLR 2024)
MISGENDERED: Limits of Large Language Models in Understanding Pronouns
by Tamanna Hossain
(ACL 2023)
PYLON: A PyTorch Framework for Learning with Constraints
by Kareem Ahmed
(AAAI 2022 Demo)
Counterfactual Explanations Can Be Manipulated
by Dylan Slack
(NeurIPS 2021)
Reliable Post hoc Explanations Modeling Uncertainty in Explainability
by Dylan Slack
(NeurIPS 2021)
Data Importance-Based Active Learning for Limited Labels
by Pouya Pezeshkpour
(CVPR VL3 Workshop 2020)
Investigating Robustness and Interpretability of Link Prediction via Adversarial Modifications
by Pouya Pezeshkpour
(NAACL 2019)
"Why Should I Trust You?": Explaining the Predictions of Any Classifier
by Marco Tulio Ribeiro
(KDD 2016)
Combining Feature and Instance Attribution to Detect Artifacts
by Pouya Pezeshkpour
(ACL Findings 2022)
An Empirical Comparison of Instance Attribution Methods for NLP
by Pouya Pezeshkpour
(NAACL 2021)
MOCHA: A Dataset for Training and Evaluating Generative Reading Comprehension Metrics
by Anthony Chen
(EMNLP 2020)
COVIDLies: Detecting COVID-19 Misinformation on Social Media
by Tamanna Hossain
(NLP-COVID Workshop at EMNLP 2020)
AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
by Taylor Shin
(EMNLP 2020)
Tweeki: Linking Named Entities on Twitter to a Knowledge Graph
by Bahareh Harandizadeh
(W-NUT at EMNLP 2020)
Gradient-based Analysis of NLP Models is Manipulable
by Junlin Wang
(EMNLP Findings 2020)
Entity Resolution by Clustering Contextualized Mention Embeddings
by Robert L. Logan IV
(ACL 2019)